A few years ago I dreamed up this delivery method for live music that seemed absurd, but somehow necessary. After experiencing the constraints of the pandemic as a developer + musician the idea became increasingly relevant, and implementation felt silly not to attempt.
This is the first post in a series of my learnings along that JavaScript journey, through which I'll primarily be surfacing low-latency frontend performance issues that are universal to building apps for the web – with a little domain-specific fun sprinkled in.
Getting to the juncture that's birthed this series has been the result of a few years of ongoing inspiration, sustained by watching the Web Audio API and Web MIDI API projects grow up (for nearly a decade now, thank you Chris R, Hongchan, Paul, Raymond, Chris W, Chris L, Myles, Matt, Ruth, Tero, et al). Throughout these years I've phased between research, demo writing, organizing related meetups, and experiencing a few significant moments of trial, error, and progress. Some of the most notable being:
- 🔊 Writing a demo to test the assumption that someone could lead a band at a music venue remotely using MIDI over WebSockets (thank you Michael, Nate, Jov, and Bret for that wonderful moment in 2016).
- 🔊 Concluding that this WebSocket waterfall transport mechanism did not need to be built on a peer-to-peer solution instead (like WebRTC data channels) to work performantly and scale, but that a lightweight WebSocket implementation would work beautifully (even if it has to make round trips to the WS server to relay user data). This outcome was supported by many conversations with core WebRTC and node developers (thank you Philipp, Jan-Ivar, Lenny, et al).
- 🔊 Understanding the limitations of JS timing APIs, and how to navigate them for this purpose (Nick*, Ben, Bryan, and Chris H).
Alright, let's get started with some context.
The Context
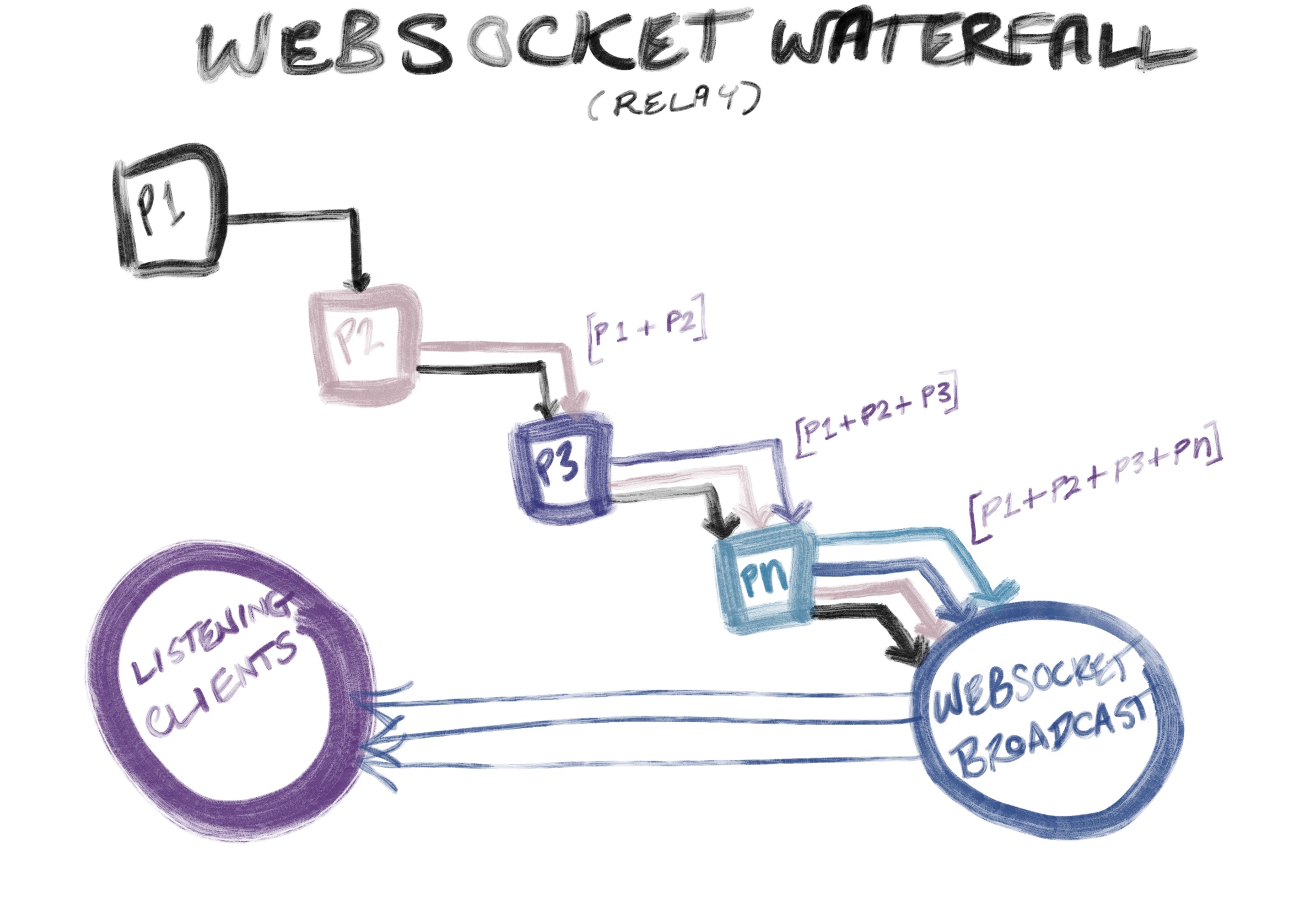
Sampling & Playback MechanismConceptually, this event sampling and playback mechanism was designed to be used unidirectionally in a relay – rather than to support an attempt at making events between clients feel bidirectionally interrupt driven. The point being that event samples from every client in the relay can continually be added during a defined chunk of time (for example: 5 seconds), and then sent to listeners when all the events have been fired by the ‘performer' clients.
At the onset, I wasn't sure if this would work. JavaScript's timer APIs are usually firing on the same call stack alongside everything else in its one, single, main thread – and this doesn't seem like a reliable setup for accurately sampling events and playing them back at high frequency intervals below a rate that's acceptable for achieving the fidelity that music requires (like 16 milliseconds or less). I mean, you can tell the JS timer APIs to run callbacks at a rate as low as a millisecond, but you're still left with the question: “is that even possible?”
Regardless, there have been a few notable examples in recent years of deterministic event scheduling in web applications (such as: sequencers, drum machines, and even basic audio multitracking with a metronome). So even though I set out on a naive foot, those projects gave me the confidence that this could be possible.
Problem One: High fidelity event sampling
The idea was to be able to trigger MIDI events (using the Web MIDI API) in a way that could be either sent to the next client at exactly the same duration of time as it was performed (which is likely impossible), or to capture the events in small chunks of time and replay them them on the next client immediately, in series. Going with the latter meant that the first problem at hand was to figure out how to accurately capture a stream of MIDI events as they occurred, along with a timestamp indicating when they happened for later use.
What didn't work? Timers.
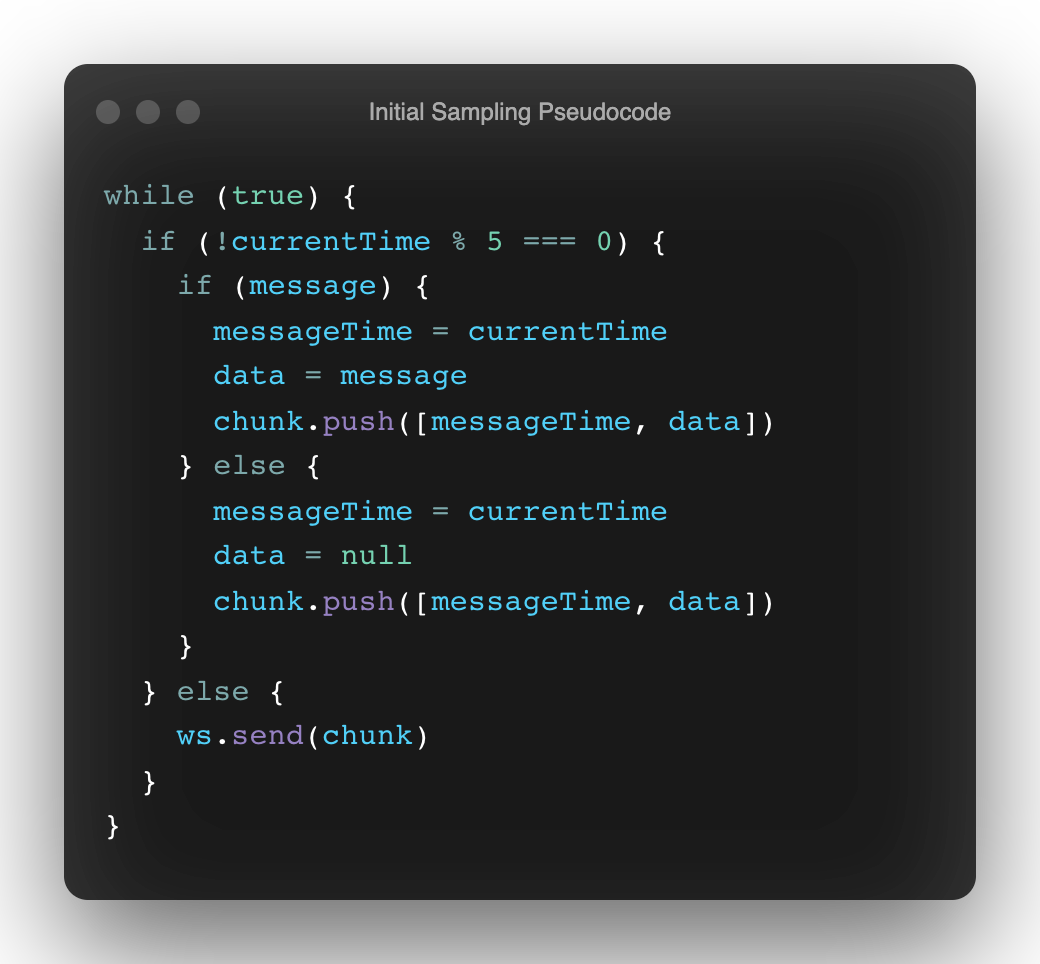
Instead of starting on a sensible foot: like using a standard Web API that runs a predictably repeating function to capture highly accurate time samples from the Web Audio API's audioContext.currentTime – I headed in a direction of looping bliss:
 Initial Sampling Pseudocode
Initial Sampling PseudocodeThis is a nice thought, but an infinite sampling loop like this is doomed to create way too much data, and weigh down the main thread (or even blow up its call stack).
The next natural iteration was to reach for a JS timer-based API that facilitates calling a callback repeatedly at a defined interval – like setInterval.
 Using setInterval
Using setIntervalIn the app load event here, this sampling process attempts to generate samples at about every millisecond (there was no inherent reason to use that frequency, other than to see how dependable setInterval was for this operation).
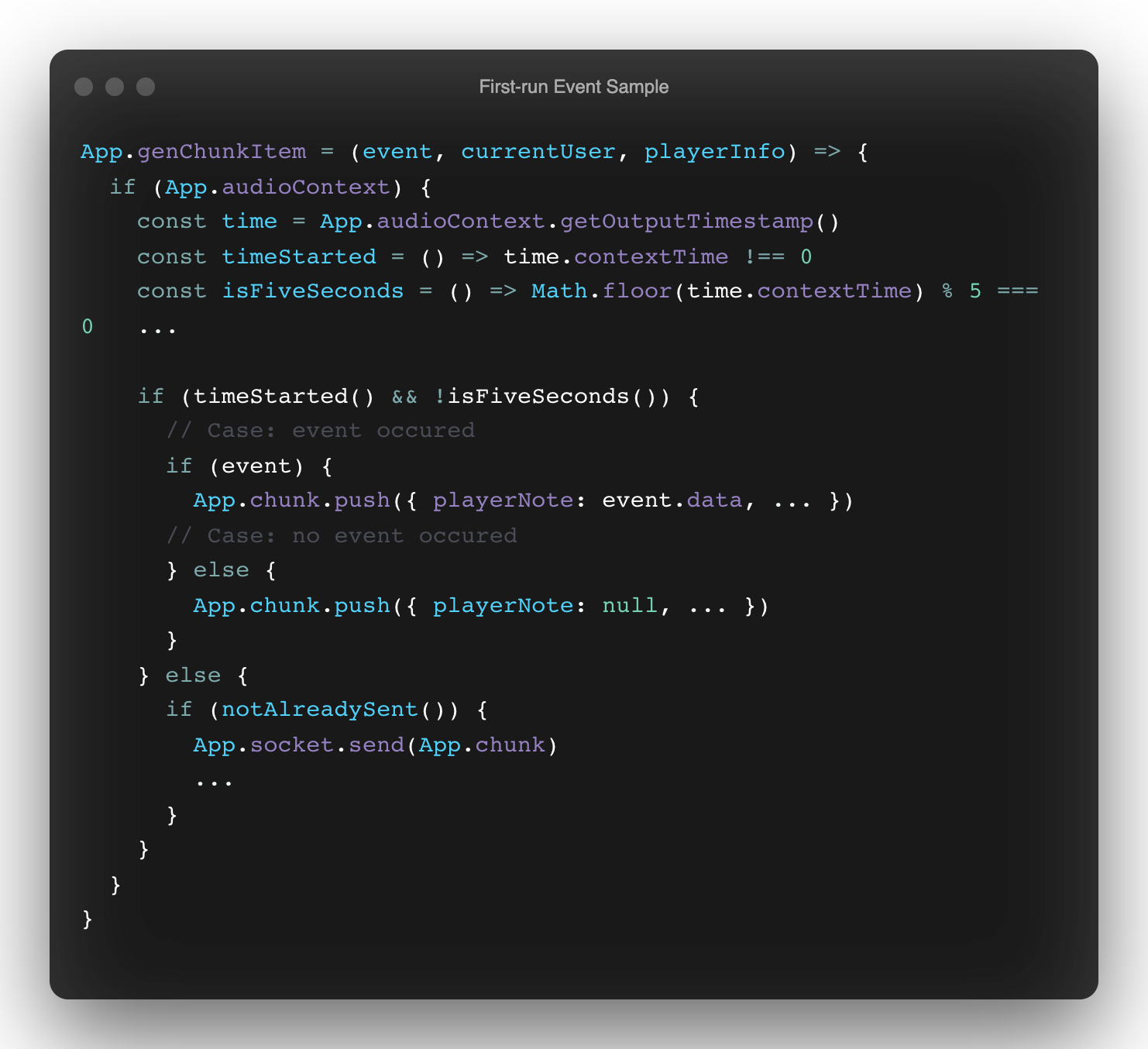
The feasible way to catch the 5 second mark for each chunk was to use the audioContext's currentTime counter (via the contextTime returned by getOutputTimestamp). This is where you start to see setInterval's scheduling accuracy break down.
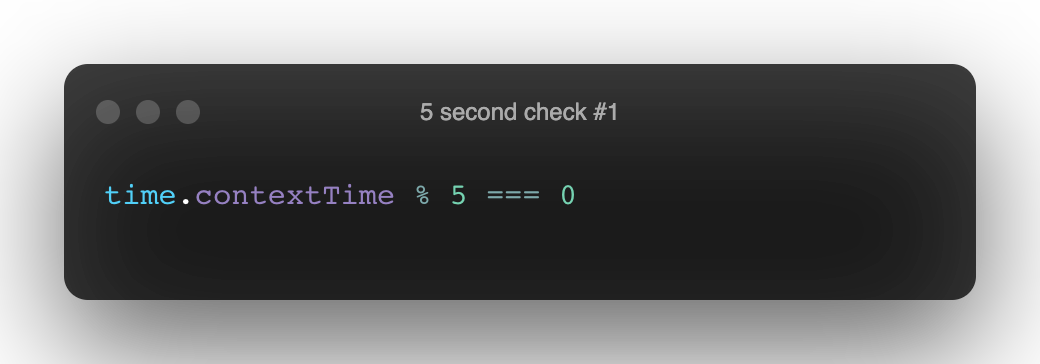
 Capturing an accurate time period for each chunk hinges on the time.contextTime % 5 === 0 check
Capturing an accurate time period for each chunk hinges on the time.contextTime % 5 === 0 checkSimply checking for 0 ensures that the condition will never be met, because the contextTime will rarely (if ever) be perfectly divisible by an integer.
 This will likely never return true
This will likely never return trueThis is because the timer that's currently used will never call the callback that gets the context time at exact intervals of 1 millisecond. For example, the integer 5 could be stuck somewhere in a transition from 4 to 5 that was off by ~0.005, as it is here between these genChunkItem callback calls:
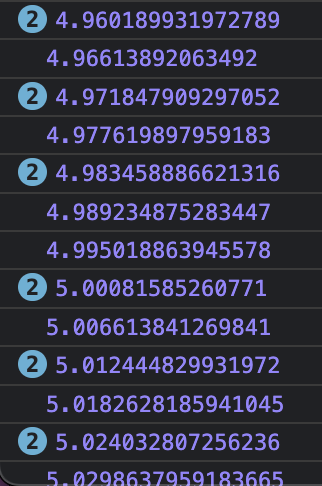 contextTime logs
contextTime logsThough necessary, flooring the timestamp is also problematic without introducing additional workarounds.
 This will return true, but for an entire second
This will return true, but for an entire secondEven though this subtle complexity has been added by flooring the contextTime, it doesn't mean that this check is a bad one. The issue is the underlying conditions that were set up for the check to be called in, which can be seen more clearly by measuring the time between genChunkItem calls:
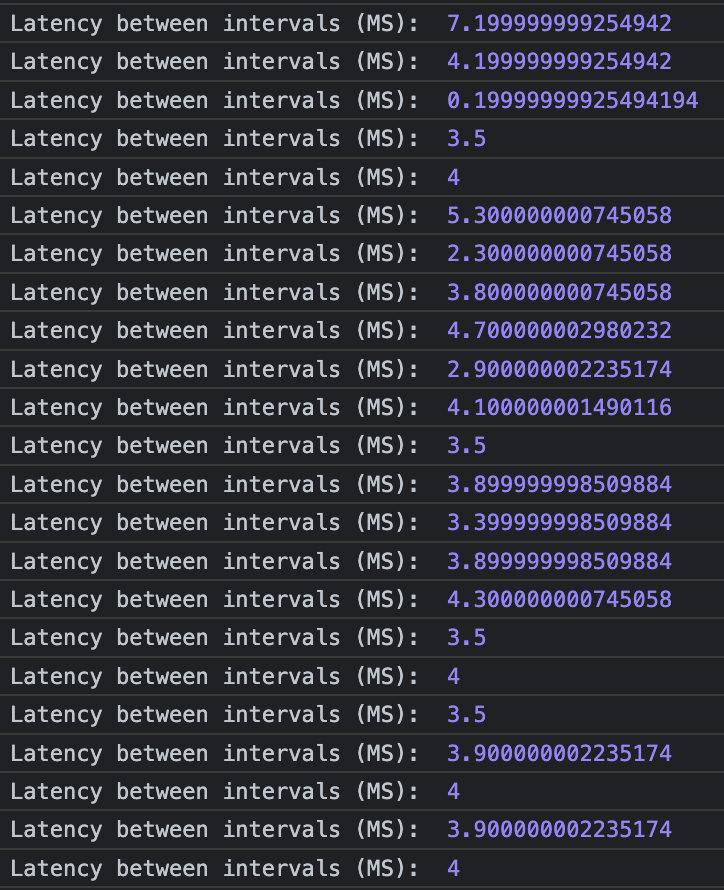 The time between ‘1ms' setInterval calls range from less than 1ms to more than 7ms
The time between ‘1ms' setInterval calls range from less than 1ms to more than 7ms(measured with performance.now())
This is where it pays to understand how JavaScript targets time, and not to just assume that JS can predictably operate on a precise time scale.
Here the trick is that a check like isFiveSeconds can't be used alone in order to capture the moment when a chunk of samples needs to be sent. In an environment with no exact timing guarantees: it should be used as the condition to fire a latching function that only allows the chunk to be sent the first time the check returns true.
This case seems to perfectly illustrate that the problem with setInterval (and JS timing in general really) is that using a standard timer API for handling precision events will never work. You can try to hit that mark, but you're going to miss it since there's no way to guarantee that your operation is going to be executed on the call stack at exactly every millisecond (let alone at greater intervals). The same rule applies for setTimeout as well.
 JS Timers, in a nutshell
JS Timers, in a nutshellJavaScript timers can only run at an estimated interval, and the reason for this is that even though a callback can be scheduled by these APIs to run on a set timer, other tasks are likely going be running when that time arrives – and the callback will have to wait its turn. This reality is even loudly noted near the top of the HTML timer specification, stating that “delays due to CPU load, other tasks, etc, are to be expected.”
Since estimation is at play when scheduling work to be done, it's easy to see that setInterval and other JS timers will also bring fundamental issues to the table that they're not really equipped to solve: like clock synchronization.
To demonstrate this (and what you should not do), here's a rudimentary chunk playback server that kicks off ANOTHER setInterval timer in an attempt to send over the event samples that were captured to the other clients (in this case, it's a simple WebSocket broadcast for testing the accuracy of playback timing locally first).
 Now we have two separate, undependable clocks 🤦
Now we have two separate, undependable clocks 🤦Unfortunately, this new timer's ability to playback events at exactly the same times they were captured will never be possible since setInterval won't be able to run through the exact same set of time intervals twice (especially at a high resolution). It's also worth noting that additional complications may ensue here since one timer is executing in the browser, and another is in node's event loop (which will now keep running as long as the timer is active). Both versions of setInterval use different timing mechanisms, and have very different speed averages.
 setInterval accuracy test
setInterval accuracy testRunning this simple accuracy test on both platforms returned a 6ms average for drift around the 16ms interval target in the browser, and a 2.5ms average drift in node (note: this speed difference is also due to circumstances extrinsic to JS runtime performance, like Spectre vulnerability mitigation).
So instead of instantiating multiple, unsynchronized clocks, and continually pushing new work to the stack (which will slow it down, and make execution time unpredictable) – wouldn't it be better to only use one source of truth for precision timing, and correlate that with the most dependable, high frequency task that's already happening at regular intervals in the browser?
Well yes it would be, and that's exactly what can be done to make this work! It turns out that this is possible if you don't try to time your events precisely using these APIs, but shift your focus to precisely measuring the time the events occurred by ensuring they all rely on the shared high-resolution time that's available, and are utilizing a correct time-offset to account for each client's local time.
What did work? Reliable Tick Targeting & Measuring Offsets.
If you've been around the block with Node.js before, the first API that likely comes to mind for accurately scheduling events as close to the tick as possible is process.nextTick. It's in the right category of functions to consider here, but at this point it's clear that:
- Generating high-resolution timestamp samples that are accurately correlated to user events shouldn't be done anywhere else but in the client.
- This kind of method still creates new ticks (work), rather than referencing existing ones.
This will also rule out Web APIs like queueMicrotask because microtasks will stall the browser by queuing up work at the tail of the current tick, rather than at the next one.
postMessage (which can be called with window.origin) is a very high-frequency API, and would be a better choice than opting for setTimeout (a throttled API) – and the results of this postMessage example from Jan-Ivar Bruaroey shows that the API will execute around 100-140 times more frequently than setTimeout(0). Still though, both of these APIs add work to the current process (even if they are scheduled for the next tick).
So, how are we going to get around this and use existing work instead? The answer is requestAnimationFrame.
 Looks dangerous, but this is async recursion under the hood – so you won't blow the stack.
Looks dangerous, but this is async recursion under the hood – so you won't blow the stack.Using requestAnimationFrame, captureSamples now gets called according to the refresh rate of the browser, which should just about always be happening at a dependable 60 times per second (for more detail, read here).
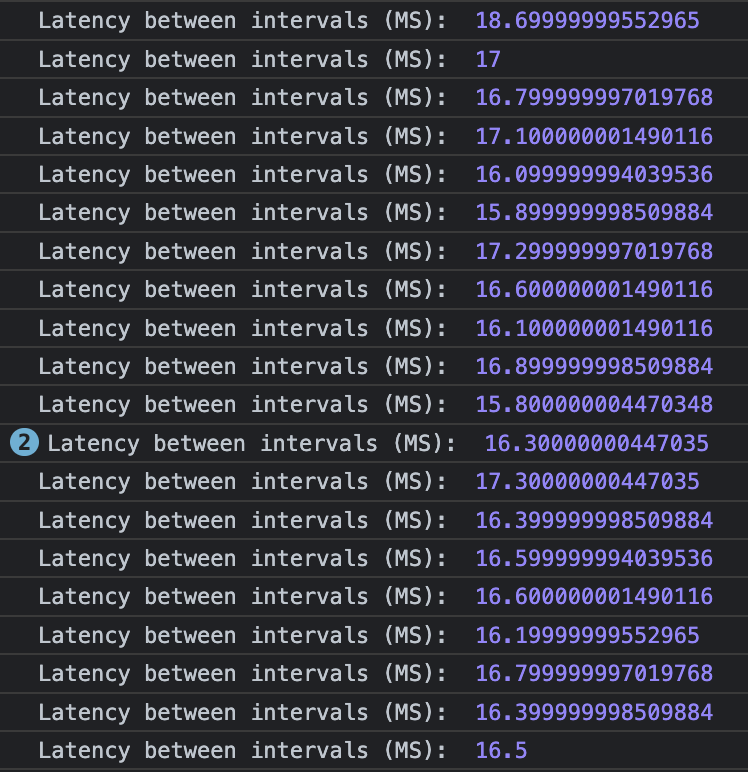 16ms intervals now fire with about 70% accuracy, and the remaining intervals are only off by around 1ms (that's 272ms less than the current average human reaction time)
16ms intervals now fire with about 70% accuracy, and the remaining intervals are only off by around 1ms (that's 272ms less than the current average human reaction time)This will end up generating a new sample about every 16 milliseconds, and if the same method is used for playback – the events will be performed again at intervals very close (or close enough) to the rate they were sampled (and are perceived as identical).
Another key factor here is that requestAnimationFrame uses the same DOMHighResTimeStamp that both the Web Audio context and timestamp retrieval APIs like performance.now use (they all return double precision, floating point numbers). This is going to be required for accuracy when making offset-oriented synchronization calculations for the timing between clients.
Now that I have requestAnimationFrame humming along smoothly, I can confidently run my time check (isFiveSeconds), offset the calculation for each MIDI packet producing event (aka, a 'note'), and rely on my latching method in the sample capture function (more on offsets coming in the next section).
 A more dependable and accurate event sampler
A more dependable and accurate event samplerNote: though based on a DOMHighResTimeStamp, the contextTime returned by the audioContexts getOutputTimestamp API returns time in seconds rather than milliseconds and must be multiplied or divided by 1000 accordingly. ¯\_(ツ)_/¯
Being able to hook into and rely on a process as fundamental as the browser's refresh rate with requestAnimationFrame has enabled a much more rock solid mechanism for event sampling.
Now that I've verified that this is going to work, let's pull back the curtain a bit and recognize that this isn't actually sampling anymore. What I've done is to generate events based on MIDI triggers (keypresses, MIDI device output, etc). I've had two loops until now, and it turns out that the playback loop may be the only one that's necessary as long as the event times and offsets are captured and sent every 5 seconds. The events only really need to be recorded when they happen, rather than within a stream of time samples that contains both events and non-events.
By calculating offsets, this same result could even potentially be achieved using a timer API like setInterval or setTimeout. These accuracy tests show that no matter how you schedule an event in JavaScript, you have to accept that there will always be variants and drift in your callback time. You can't expect that the delay will be a true and accurate representation of the time you assigned to it, but you can anticipate and account for it in order to schedule events at times you can rely on.
Problem two: Precise sample playback
As was learned earlier, attempting to correlate two clocks between the client and the server by using setInterval to schedule the playback was never going to work. But even with requestAnimationFrame in play and offsets taken into account, some nuances have to be dealt with.
What didn't work?
When you're new to an API and you start porting over examples from common reference sources, it's easy to introduce unnecessary calls just because you're presented with them as an option.
 Lesson: don't just use API calls that look necessary without considering what you actually need in your scope first.
Lesson: don't just use API calls that look necessary without considering what you actually need in your scope first.Here requestAnimationFrame returns an ID that can be used for canceling an animation frame request that was already scheduled, but is it needed here? No. The call to window.cancelAnimationFrame, serves no purpose in this case because no request is currently scheduled there.
Despite that, the most important question to answer here in this example is: what's the best way to calculate the duration of each event for playback? In this iteration, an attempt to calculate the time between each sample was made in order to play them back at those exact intervals (using data[i].noteDuration). Though, there's much more room for error here than if the question at hand is answered through a different approach.
What worked?
Rather than handling event playback timing by the interval (like a sample), the better way to do this is by capturing the chunk's offset once per data received (eg. a chunk of captured events) based on the current context time, and the first event that's about to be played back. This way no event fidelity is lost for any client, and each one is lined up to be played back exactly as it was originally performed (as far as humans can tell).
 Accurate and dependable sample playback
Accurate and dependable sample playbackHaving an accurate event sampling (or, capturing) and playback method now ensures that any notes played by one user can be rendered and heard by the others just as they were originally played – but that only gets us half way to making music together. How do you accurately synchronize the playback across browsers for every player so they can actually play together?
So far, what's been made is a vital piece of orchestration to accompany a relay server – and that server will be the second half of the answer to this question. We'll walk through it in depth in part two of this series: Distributed event synchronization with Vanilla JavaScript and WebSockets.
* Special thanks to Nick Niemeir, for the early mornings and late night fun (via Amsterdam / Portland) as we got this working together!




